
Transformation with oXygen Scenario TEI P5 DOCX
Updated 07.08.25 CR
IMPORTANT!
Do not use the function "Track Changes" in the word file. This will create unwanted tags and white spaces in the TEI version.
Only add the links from the foot notes in the respective citation, and delete the foot notes and their references in Word.
- Inhaltsverzeichnis
- Word in SVN
- Pre-Processing Word
- Word to TEI Transformation in oXygen
- Pipeline example
- Structures
- Final version for online publication
Word in SVN¶
- Save original Word document in oXygen under SVN/trunk/teiedit/lemma-edit/orig/
- Create a new folder for the lemma under SVN/trunk/teiedit/lemma-edit/build/ and save a build.xml file to start the pipeline.

The build.xml file can be copied from an older build.xml and replace links and file names with the new ones. To start the new pipeline, use the target name="finalize"
Example of build.xml from L0007:
<?xml version="1.0" encoding="UTF-8"?>
<project basedir="." name="L0007" default="finalize">
<!--Pipeline for the lemma ALEA. 21.03.24 CR
DOCX2TEI
-->
<property name="diff.dir" value="diff"/>
<property name="log.dir" value="log"/>
<property name="xml.dir" value="xml"/>
<property name="docx.dir" value="docx"/>
<property name="xsl.dir" value="xsl"/>
<property name="xslt.log" value="${log.dir}/${ant.project.name}_xslt.log"/>
<property name="xslt.processor" value="../../../lib/xsltproc/Saxon-HE-9.8.0-12.jar"/>
<property name="xslt.class" value="net.sf.saxon.TransformerFactoryImpl"/>
<property name="orig.file" value="../../orig/Alea_L0007/2024-02-22-Alea_lektorierte_Endfassung.docx"/>
<!--Copy original file to the docx folder as _000.docx / _v1-0.docx-->
<target name="initialize">
<echo>Initializing L0007.</echo>
<mkdir dir="${xml.dir}"/>
<mkdir dir="${log.dir}"/>
<copy file="${orig.file}" tofile="${docx.dir}/L0007_000.docx"/>
<!--L0007_000.docx: copy of original Word document from author "2024-02-22-Alea_lektorierte_Endfassung.docx"-->
</target>
[...]
<target name="finalize" depends="initialize">
<echo>Reached end of pipeline.</echo>
</target>
This process will create a folder docx and a copy of the original word document in this case ” 2024-02-22-Alea_lektorierte_Endfassung.docx” as “L0007_000.docx” in the pipeline. It is useful to avoid damaging the original.
Pre-Processing Word¶
- Save the Word document L0007_000.docx as L0007_001.docx
- L0007_001.docx is used for manual changes and tagging of specific text parts (toc, citations, save links from footnotes in the citation, etc.).
IMPORTANT!
Do not use the function "Track Changes" in the word file. This will create unwanted tags and white spaces in the TEI version.
Only add the links from the footnotes in the respective citation, and delete the footnotes and their references in Word.
| If there is no table of contents: Adding format templates for headings in all levels |
 |
| Adding table of contents |  |
| Adding links from footnotes inline and delete all footnotes from the Word document |    |
| Adding format to citations without links in footnotes. |   |
| Adding format for terms |   |
| Also add terms for words after arrows "->" |  |
Word to TEI Transformation in oXygen¶
1. Open L0007_001.docx in oXygen
2. From the files, open “styles.xml” and run the transformation DOCX TEI P5
3. This will save a TEI file “L0007_001-TEI-P5.xml” in docx folder.
![]()
The newly transformed file “L0007_001-TEI-P5.xml” should be saved in the xml folder as “L0007_001.xml”.
This is the file used for structural annotation and further manual changes.
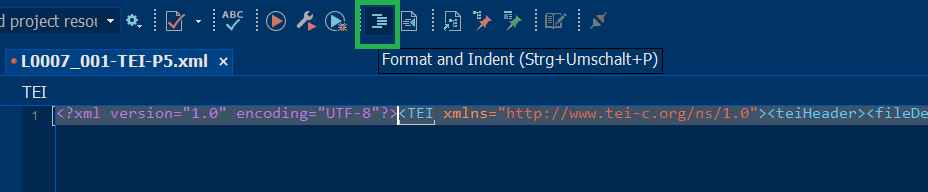
As
a result of the oXygen Transformation DOCX TEI P5, this file is
rendered in a line, to indent: Select > Format and Indent file
“L0007_001.xml”
Unwanted newlines¶
After the transformation some text has unwanted new lines.

To improve processing and readability:
Select <text> and press ctrl + f to open the window “Find/Replace”.
In Find write \n space + “\n +”.
In Replace space “ ”, write //p in the XPath line. Press Find All, Replace all. Close and save.

All <p>(s) are now in a line.

Do the same for the elements <head>, <list>, <item>
Pipeline example¶
Details about the TEI-Text edition, XSL-Transformations and information about how the structures should be tagged:
SVN/trunk/teiedit/lemma-edit/build/L0007/build.xml

Resources: The templates and lists:
SVN/trunk/teiedit/lemma-edit/resources/
Validation with help of a Schematron is in progress and should be improved to avoid structure errors:
SVN/trunk/teiedit/lemma-edit/resources/validation/SvSal-Lemma-validation.sch
Structures¶
Structural annotation_
- front
- body
- back
- div(s) @type section
@n for each content numeration
<div type="section" n="1" xml:id="L0002-d1-03e9">
<head xml:id="L0002-he-03e8">1 Definition and context</head>
[...]
<div type="section" n="2" xml:id="L0002-d1-03ed">
<head xml:id="L0002-he-03eb">2 Acceptio personarum in the School of Salamanca</head>
- div(s) @type subsection for lower-level numbering
<div type="subsection" n="2.1." xml:id="L0002-d2-0519">
<head xml:id="L0002-he-03ec">2.1. Defining acceptio personarum</head>
[...]
<div type="subsection" n="2.4" xml:id="L0002-d2-0523">
<head xml:id="L0002-he-03f6">2.4 Acceptio personarum in the Indies</head>
Attention
No @n attribute for div(s) without numeration.
<body xml:id="L0002-tb-03e8">
<div type="section" n="1" xml:id="L0002-d1-03e9">
<head xml:id="L0002-he-03e8">1 Definition and context</head
<!--Error--> <div type="subsection" n="" xml:id="L0002-d2-0515"><p n="1" xml:id="L0002-pa-03ea">The authors of the School of Salamanca define acceptio personarum
<!--It should be:--><div type="subsection" xml:id="L0002-d2-0515"><p n="1" xml:id="L0002-pa-03ea">The authors of the School of Salamanca define acceptio personarum
- (“\w+”) -> <quote>$1</quote> should not appear inside <bibl> for instance “Ludus”
- the rest by finding “\w+
- double space " " -> in one space " "
- if words starting with → were not tagged in word as <hi rend="Term">, use <g style="font-family:Wingdings;" n="F0E0"/> (in Word →) -> <term>...</term>
- Short citations: <bibl><biblScope>SP 1.5.57</biblScope></bibl> and <bibl><biblScope>1.6.34</biblScope></bibl>
- Added type="section", type="subsection" in div(s)
- correct <head>\n titles in one line.
- deleted </seg><seg rend="smallcaps"> so it remains smallcaps as <seg rend="smallcaps">[Name]</seg>
- in div[@type eq 'sources'], <p><ref>..</ref></p> with only links belong to a preceding::p.
- Change first name lastname to lastname, firstname
use regex:
(<hi rend="cite-rec-body">)(\w+)(\s+)(<seg rend="smallcaps">\w+</seg>) replace with $1$4,$3$2
(<hi rend="cite-rec-body">)(\S+)(\s+)(<seg rend="smallcaps">\w+</seg>) replace with $1$4,$3$2
e.g. <hi rend="cite-rec-body">Melchior <seg rend="smallcaps">Cano</seg>
should be:
<hi rend="cite-rec-body"><seg rend="smallcaps">Cano</seg>, Melchior
(<hi rend="cite-rec-body">)(\S+\s+\w+)(\s+)(<seg rend="smallcaps">\w+</seg>) replace with $1$4,$3$2
<hi rend="cite-rec-body">Luis de <seg rend="smallcaps">Granada</seg>
should be:
<hi rend="cite-rec-body"><seg rend="smallcaps">Granada</seg>, Luis de
(<hi rend="cite-rec-body">)(\S+\s+\w+)(\s+)(<seg rend="smallcaps">\S+\s+\S+</seg>)
The rest manually
- Check each reference are in only 1 <ref> element. For instance:
<ref target="https://id.salamanca.school/texts/W0002:16.1.number3?format=html">Azpilcueta 1556, cap. 16 no. 3, p. 160</ref>
If it looks like:
<ref target="https://id.salamanca.school/texts/W0002:16.1.number3?format=html">Azpilcueta</ref><ref target="https://id.salamanca.school/texts/W0002:16.1.number3?format=html" xml:space="preserve"> 1556, cap. 16 no. 3, p. 160</ref>
Reduce it with regex. Ctrl+f </ref><ref target=".*?"> and/or </ref> <ref target=".*?"> replace with nothing
Table of contents / @targets¶
These @targets should go to <div>(s)/@xml:id(s). From the transformation in oxygen they lead to <head>(s). This was updated manually for L0007.xml
<div type="contents" xml:id="L0007-div-d1e107"> <list xml:id="L0007-li-d1e107"> <head xml:id="L0007-he-e171">Contents</head> <item xml:id="L0007-it-d1e115"><ref target="#L0007-div-d1e173">1 Definition and context</ref></item> [...] <body xml:id="L0007-body-d1e171"> <div type="section" n="1 Definition and context" xml:id="L0007-div-d1e173">Do not forget title in <head> and contents in <item>
<front xml:id="L0072-fm-03e8">
<div type="contents" n="contents" xml:id="L0072-d1-03e8">
<list xml:id="L0072-li-03e8">
<head xml:id="L0072-he-03e8">Fornicatio</head>
<item xml:id="L0072-it-03e8">Contents</item>
TEI-All to SvSal-TEI¶
Use XSL-Transformation = [SVN]/trunk/teiedit/lemma-edit/resources/templates/xsl/TEI-Transformation-SvSal.xsl
See [SVN]/trunk/teiedit/lemma-edit/build/L0072/xsl/L0072_001.xsl as example.
<target name="xslt-001"> <!--depends="patch-001"-->
<echo>Transformation TEI-P5 to SvSal-TEI.</echo>
<record name="${xslt.log}" action="start" loglevel="verbose"/>
<xslt force="true" in="${xml.dir}/L0072_001.xml" out="${xml.dir}/L0072_002.xml" style="${xsl.dir}/L0072_001.xsl" classpath="${xslt.processor}">
<factory name="${xslt.class}"/>
</xslt>
<record name="${xslt.log}" action="stop"/>
</target>
Annotate names, autors as author/persName and SvSal authors with gnd links.¶
See [SVN]/trunk/teiedit/lemma-edit/resources/templates/xsl/persName-Tagger.xsl
<target name="xslt-002" depends="xslt-001">
<echo>Annotate names, autors as author/persName and SvSal authors with gnd links.</echo>
<record name="${xslt.log}" action="start" loglevel="verbose"/>
<xslt force="true" in="${xml.dir}/L0072_002.xml" out="${xml.dir}/L0072_003.xml" style="${xsl.dir}/L0072_002.xsl" classpath="${xslt.processor}">
<factory name="${xslt.class}"/>
</xslt>
<record name="${xslt.log}" action="stop"/>
</target>
<persName> in outside <bibl>¶
Salamanca authors:
<p> [...] both expressing disapproval of gambling. In fact, <persName ref="https://d-nb.info/gnd/118798111">Soto</persName> interprets [...] </p>
If the references are unknown:
<p> [...] Unlike medieval authors like <persName>Aquinas</persName>, <persName>Bonaventura</persName>, <persName>Hostiensis</persName>, etc., [...] </p>
<term>¶
Words preceded by arrows: ➜ excommunicatio
<term xml:id="L0007-term-d1e693">excommunicatio</term>
body//bibl¶
With links to Salamanca collections:
<bibl corresp="https://id.salamanca.school/texts/W0041:1.64.1?format=html" xml:id="L0007-bibl-d1e183">
<author>
<persName ref="https://d-nb.info/gnd/120148226">Díaz de Luco</persName>
</author>
<date when="1554">1554</date>,
<biblScope>cap. 64, p. 125</biblScope>
</bibl>
Without links:
<bibl xml:id="L0007-bibl-d1e321">
<author>
<persName ref="https://d-nb.info/gnd/119442523">Salas</persName>
</author>
<date when="1617">1617</date>,
<biblScope>dub. 1 no. 3, p. 640</biblScope>
</bibl>
Currently, <persName>(s) have only @ref, they should also have @key:
<bibl corresp="https://id.salamanca.school/texts/W0096:vol1.2.10.14">
<author>
<persName ref="https://d-nb.info/gnd/118837389" key="Solórzano Pereira, Juan de">Solórzano</persName>
</author>
<date when="1629">1629</date>, <biblScope>lib. 2 cap. 10 no. 26, p. 354</biblScope>
</bibl>
back//bibl¶
Smallcaps <hi rendition="#sc"> for last names and Links with ref//@target¶
Currently, persName in Literature section (back) are manually tagged.
<bibl xml:id="L0007-bibl-d1e1217">
<author>
<persName ref="https://d-nb.info/gnd/118768735">
<hi rendition="#sc">Vitoria</hi>, Francisco de</persName></author>:
<title>Confessionario</title> (
<date when="2018">2018</date> [
<date when="1562">1562</date>]), in: The School of Salamanca. A Digital Collection of Sources <
<ref target="https://id.salamanca.school/texts/W0015">https://id.salamanca.school/texts/W0015</ref>></bibl>
<bibl xml:id="L0007-bibl-d1e1245">
<author>
<persName>
<hi rendition="#sc">Carpenter</hi>, Dwayne E.</persName></author>:
<title>Fickle Fortune: Gambling in Medieval Spain, in: Studies in Philology 85</title> (
<date when="1988">1988</date>), 267–278.
</bibl>
@target without '#'
Error: <ref target="#https
should be: <ref target="https
"Literature" Headers¶
<head>(s) should be direct after <div>(s) and not inside <list>(s)
<back xml:id="L0007-back-d1e803">
<div type="sources" n="Literature" xml:id="L0007-div-d1e805">
<head xml:id="Toc160700182">Literature</head>
<div type="sources" n="Sources" xml:id="L0007-div-d1e811">
<head xml:id="Toc160700183">Sources</head>
<list xml:id="L0007-li-d1e811">
<item xml:id="L0007-it-d1e817"><bibl xml:id="L0007-bibl-d1e817"><author><persName ref="https://d-nb.info/gnd/133542521"><hi rendition="#sc">Avendaño</hi>, Diego de</persName></author>: [...]
Final version for online publication¶
The final and most updated versions are stored in:
SVN/trunk/svsal-tei/lemmata/
Von Cindy Rico Carmona vor weniger als 1 Minute aktualisiert · 36 Revisionen